How to install Apache HBase on Ubuntu?

Hey guys,
In this article, I will explain how to install Apache HBase in standalone mode on a Hadoop cluster. I will provide step by step instructions to set up HBase on Ubuntu 16.04. So, if you are looking to make your hands dirty on Apache HBase, this article can be a steppingstone for you. The agenda for discussion is as follows:
· What is Apache HBase?
· Step by step HBase installation
· Test HBase
So, let us begin…
What is Apache HBase?
Apache HBase is a distributed large data store that is open-source, and it is a NoSQL database. It offers real-time access to petabytes of data in a random, strictly consistent manner. HBase excels in dealing with huge, sparse datasets. HBase works on top of the Hadoop Distributed File System (HDFS) or Amazon S3 utilizing the Amazon Elastic MapReduce (EMR) file system and interacts easily with Apache Hadoop and the Hadoop ecosystem.
HBase does support SQL. But HBase can interact with Apache Phoenix to provide SQL-like queries over HBase tables and serves as a direct input and output to the Apache MapReduce framework for Hadoop. HBase is a non-relational database with a column-oriented design. Data is kept in distinct columns and is indexed using a unique row key. This design enables quick retrieval of individual rows and columns inside a table, as well as fast scans over individual columns. The data and queries in an HBase cluster are dispersed over all servers, allowing you to query results on petabytes of data in milliseconds.
HBase is best for storing non-relational data that can be retrieved using the HBase API (Application Programming Interface). Apache Phoenix is often used as a SQL layer on top of HBase, allowing you to insert, remove, and query data saved in HBase using familiar SQL syntax.
Step by step installation of HBase on Ubuntu
Pre-requisite:
· Ubuntu 16.04 or higher installed on a virtual machine.
· Hadoop installation (How to install Hadoop installation click here)

Steps for installation of Apache HBase
Step 1
Download HBase: To download HBase stable version, run the following command:
$ wget https://archive.apache.org/dist/hbase/stable/hbase-2.4.12-bin.tar.gzStep 2
To untar the HBase file run the following command:
$ tar xzvf https://archive.apache.org/dist/hbase/stable/hbase-2.4.12-bin.tar.gzStep 3
Navigate to hbase-2.4.12/bin:
$ cd hbase-2.4.12/binSet Java path: To set java path for HBase environment run the following command:
$ sudo nano conf/hbase-env.shAnd add the java path (below given) at the end of the and save it.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64Step 4
To start HBase: run the following commands:
$ cd hbase-2.4.12/bin$ ./start-hbase.sh
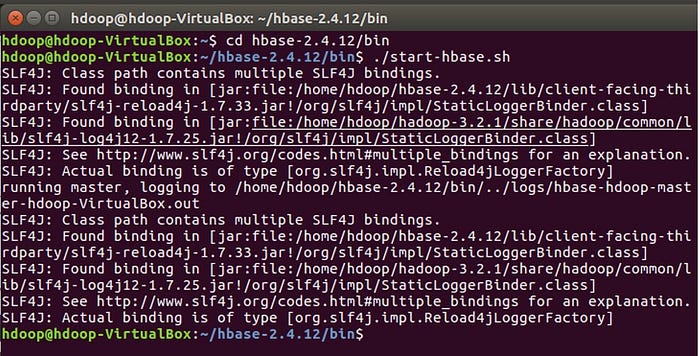
Go to http://localhost:16010 to view the HBase web user interface.
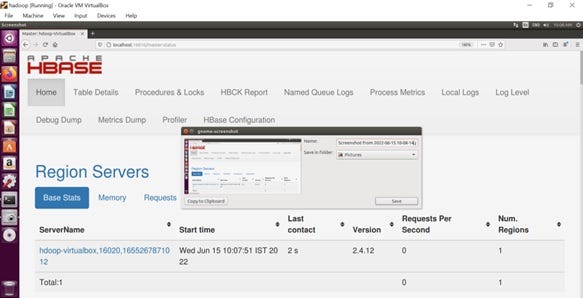
Step 5:
Connect to HBase shell: Connect to the instance of HBase use the hbase shell command, located in the bin directory.
$ ./hbase shell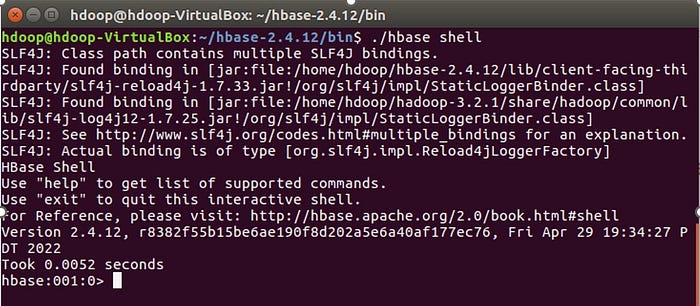
Step 6:
To create a table: Use the create command to create a new table. It is mandatory to specify the table name and the ColumnFamily name.
>create ‘MyDatabase’, ‘cf’Step 7:
Use the list command to check that the table exists or not.
>list ‘MyDatabase’Step 8:
Use the describe command to see details of the table
>describe ‘MyDatabase’
Step 9:
To insert data into your table, use the put command:
>put ‘MyDatabase’, ‘row1’, ‘cf:a’, ‘10001’>put ‘MyDatabase’, ‘row2’, ‘cf:b’, ‘Virendra’>put ‘MyDatabase’, ‘row3’, ‘cf:c’, ‘200000’

Step 10
Use the scan command to scan the table for data.
>scan ‘MyDatabase’Step 11
To get a single row of data at a time, use the get command.
>get ‘MyDatabase’, ‘row1’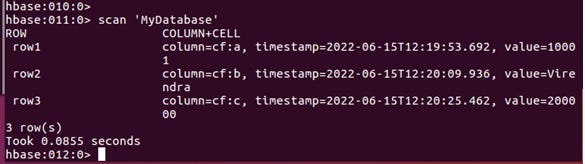
Step 12:
Disable a table — If you want to delete a table or change its settings, you need to disable the table first, so use the disable command for this purpose. You can re-enable the table using the enable command.
>disable ‘MyDatabase’>enable ‘MyDatabase’
Step 13:
Drop the table: To drop (delete) a table, use the drop command.
>drop ‘MyDatabase’Step 14
Exit from HBase Shell: To exit from the HBase Shell and disconnect from your cluster, use the quit command. However, HBase is still running in the background
Step 15
Stop HBase: To stop all HBase daemons, you can run ./stop-hbase.sh script.
$ ./stop-hbase.shConclusion
In this article, I have presented step by step process to set up Apache HBase on Ubuntu 16.04. It is super simple to install HBase on Hadoop cluster. Hope you would successfully set up Apache HBase on your system.
On wrapping up notes, feel free to share your comments. Your likes and comments will help me to present contents in better way. See you next week.
More content at PlainEnglish.io. Sign up for our free weekly newsletter. Follow us on Twitter and LinkedIn. Check out our Community Discord and join our Talent Collective.

